Publicatiedatum: 6 februari 2014
Twitter als basis voor taalkundig onderzoek
“Ook op Blue Monday zijn we een vrolijke twittervolk”, kopte de Volkskrant op 20 januari 2014. Deze conclusie was gebaseerd op het Twittercorpus van Erik Tjong Kim Sang, postdoc onderzoeker aan het Meertens Instituut. Vorig jaar ontwikkelde hij aan het Netherlands eScience Center een website (twiqs.nl) waarmee taalkundig onderzoek gedaan kan worden aan de hand van tweets.
Door Mathilde Jansen
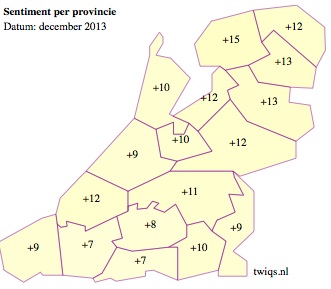 Speciaal voor de Volkskrant maakte Tjong Kim Sang een kaartje waarop je aan de hand van het woordgebruik in tweets kunt zien hoe opgewekt – of somber – er in Nederland getwitterd wordt. Vooral de Waddeneilanden scoorden hoog, waarschijnlijk door de goedgeluimde vakantiegangers aldaar.
Speciaal voor de Volkskrant maakte Tjong Kim Sang een kaartje waarop je aan de hand van het woordgebruik in tweets kunt zien hoe opgewekt – of somber – er in Nederland getwitterd wordt. Vooral de Waddeneilanden scoorden hoog, waarschijnlijk door de goedgeluimde vakantiegangers aldaar.
Limburg en Vlaanderen scoorden opvallend laag. En dat leidde tot enige kritiek op de werkwijze van Tjong Kim Sang, want in zijn woordenlijst had hij weinig dialectwoorden meegenomen. En juist in Limburg en Vlaanderen wordt nog veel dialect gebezigd. Tjong Kim Sang weet dat het systeem (nog) niet waterdicht is. Toch ziet hij allerlei mooie mogelijkheden voor taalkundig onderzoek, óók voor het bestuderen van dialecten.
Sjpassetig
De postdoc onderzoeker maakte eigenhandig een Nederlandse woordenlijst met positieve en negatieve woorden, gebaseerd op hun context in een grote hoeveelheid tweets. Leonie Cornips, taalkundige aan het Meertens Instituut en de Universiteit Maastricht trok tegen deze methode van leer in een kritische column in De Limburger :“Limburg en Vlaanderen gebruiken andere woorden dan in het Nederlands gebruikelijk is. Frou voor vrolijk en blij zal door het systeem niet herkend worden, fière en gruuts voor trots ook niet. Een woord als sjpass’ of sjpassetig in Vaals al helemáal niet.” Tjong Kim Sang geeft zijn collega op dit punt gelijk. Zijn woordenlijst bevatte wel al een reeks dialectwoorden, maar woorden als deze ontbraken nog.
De website twiqs.nl wordt vooralsnog gebruikt in een onderzoeksproject van Antal van den Bosch, computertaalkundige aan de Radboud Universiteit. Binnen zijn project wordt taalkundige informatie gebruikt om maatschappelijke problemen aan te pakken. Als er een relletje tussen voetbalsupporters op handen is, kan dit in de toekomst wellicht voorspeld worden aan de hand van het taalgebruik in tweets voorafgaand aan een wedstrijd, legt Tjong Kim Sang uit. Vanuit het Meertens Instituut zijn we natuurlijk het meest geïnteresseerd in dialectonderzoek, en daarvoor biedt het programma ook mogelijkheden, volgens de onderzoeker.
Hedde gij
Tjong Kim Sang laat zien hoe dat in zijn werk gaat. “Om dialectonderzoek te doen met twiqs.nl moet je wel kennis hebben van dialectwoorden. Je moet namelijk altijd eerst een zoekterm invoeren. Je kunt bijvoorbeeld zoeken op het Brabantse woord hedde (heb je).” Op het kaartje dat we vervolgens te zien krijgen, wordt duidelijk dat het woord vooral voorkomt in Brabant, maar ook in Amsterdamse tweets. Blijkbaar twitteren Brabanders in Amsterdam ook in het Brabants. Het computerprogramma visualiseert de gevonden data op verschillende manieren. Zo is er een mogelijkheid om een woord waarop je zoekt in een kaart te zetten. “Maar”, waarschuwt Tjong Kim Sang, “hier worden alleen die tweets meegenomen waarbij GPS-informatie beschikbaar is, en dat geldt lang niet voor alle tweets.”
Vervolgens kun je kijken welke woorden nog meer voorkomen in tweets met hedde. Daarmee kun je dus andere dialectwoorden op het spoor komen, zoals hier: wa, da en gij. Je kunt ook zien onder welke gebruikers een woord het meest voorkomt. “Per tweet maakt het programma een inschatting van de leeftijd van de twitteraar en of het een man of vrouw is, op basis van het profiel van de twitteraar. Daarin staat bijvoorbeeld: man, 34 jaar of: mama van twee kinderen.”

Niet representatief
Het systeem geeft aan dat hedde vooral wordt gebruikt door mensen onder de 18. “Maar dat is niet echt verrassend”, stelt Tjong Kim Sang. “De meeste twitteraars zijn namelijk jonge mensen. Volgens mijn informatie is de helft van de Nederlandse tweets afkomstig van personen jonger dan 18; een kwart is tussen de 18 en 25 en nog eens een kwart boven de 25.” Ook wordt er vaak gezegd dat er onder Nederlandse twitteraars meer hoger opgeleiden zijn. Daarmee moet je dus rekening houden bij het interpreteren van de data. Bovendien worden de onderwerpen waarover gesproken wordt op Twitter sterk beïnvloed door de kranten, aldus de onderzoeker. “Ook alle dagbladen zitten op Twitter en ook die berichten worden meegenomen in mijn analyses.”
 Een ander nadeel van het programma is dat het maar 50 tweets per seconde mag binnenhalen, én dat de tweets niet openbaar gemaakt mogen worden van Twitter (overigens zijn ze wel terug te vinden met een doorklik naar Twitter). Daardoor is het programma nog niet erg geschikt voor het analyseren van conversaties, zoals sommige sociolinguïsten doen. Maar als deze beperking er niet zou zijn, zou het materiaal zich hier wel voor lenen. Het taalgebruik op Twitter zit immers heel dicht aan tegen gesproken taal, en dat maakt het interessant onderzoeksmateriaal voor sociolinguïsten.
Een ander nadeel van het programma is dat het maar 50 tweets per seconde mag binnenhalen, én dat de tweets niet openbaar gemaakt mogen worden van Twitter (overigens zijn ze wel terug te vinden met een doorklik naar Twitter). Daardoor is het programma nog niet erg geschikt voor het analyseren van conversaties, zoals sommige sociolinguïsten doen. Maar als deze beperking er niet zou zijn, zou het materiaal zich hier wel voor lenen. Het taalgebruik op Twitter zit immers heel dicht aan tegen gesproken taal, en dat maakt het interessant onderzoeksmateriaal voor sociolinguïsten.
Maar voorlopig heeft onderzoek op basis van Twitter nog zijn beperkingen. Tjong Kim Sang: “Als je de Nederlandse bevolking wilt bestuderen aan de hand van tweets, zou ik zeggen: dat is geen goed idee. Het is makkelijker om incidenten te vinden dan echte patronen, tenzij je naar heel algemene dingen kijkt. Als je bijvoorbeeld zoekt op ‘eten’ krijg je een grafiek te zien met heel duidelijke pieken rond ontbijt, lunch en avondeten. Dan worden er veel data meegenomen en kun je betrouwbare conclusies trekken.”
Dit artikel is verschenen in de nieuwsbrief (februari 2014) van het Meertens Instituut. Ook interesse in de nieuwsbrief? Klik hier voor meer informatie.