Publicatiedatum: 7 maart 2014
Nieuwe mogelijkheden voor historisch taalkundig onderzoek
Op donderdag 27 maart spreekt Nicoline van der Sijs haar inaugurele rede uit aan de Radboud Universiteit Nijmegen, getiteld: De voortzetting van de historische taalkunde met andere middelen. Samen met ons blikt ze alvast vooruit op de mogelijkheden, maar ook de moeilijkheden die er nog zijn in het digitale onderzoek. Van der Sijs: “Volgens mij staan we nog maar aan het begin van de digitale geesteswetenschappen”.
door Mathilde Jansen
 De digitale geesteswetenschappen of e-humanities winnen steeds meer terrein. Maar wat er precies onder verstaan wordt is nog niet altijd even duidelijk. Volgens Nicoline van der Sijs, sinds januari 2013 hoogleraar Historische taalkunde van het Nederlands in de digitale wereld, gaat het om een containerbegrip:
De digitale geesteswetenschappen of e-humanities winnen steeds meer terrein. Maar wat er precies onder verstaan wordt is nog niet altijd even duidelijk. Volgens Nicoline van der Sijs, sinds januari 2013 hoogleraar Historische taalkunde van het Nederlands in de digitale wereld, gaat het om een containerbegrip:
“In principe kun je er al het onderzoek onder verstaan waarbij gebruikgemaakt wordt van digitale middelen, dus in zekere zin is iedere onderzoeker wel een digitale geesteswetenschapper, want iedereen werkt immers met een computer. Maar over het algemeen associeert men onderzoek in de e-humanities met grote databestanden.”
E-humanities wordt daarom al gauw gelijkgesteld aan kwantitatief onderzoek, waarbij het draait om de frequentie van voorkomen van een begrip of constructie. “Maar daarmee kun je ook heel goed kwalitatieve vragen beantwoorden. In mijn oratie geef ik als voorbeeld de vraag of de Statenvertaling bij verschijnen al archaïsch was of niet. Dat is een kwalitatieve vraag. Ik laat zien dat kwantitatieve gegevens een antwoord kunnen geven op die vraag. De uitdaging voor de onderzoeker is om de juiste kwantitatieve vragen te bedenken.”
Kritisch kijken naar de data
Voor historisch taalkundig onderzoek komt daar een extra probleem bij, namelijk de ‘ruizigheid’ van de historische data. De meeste computerprogramma’s waarmee teksten worden doorzocht en geanalyseerd, zijn gemaakt voormoderne teksten. Historische teksten vormen nog een moeilijk te nemen horde, door hun enorme spellingvariatie en vormenvariatie, en hun grotere of kleinere syntactische afwijkingen van het moderne Nederlands. Bovendien zijn veel van de oude teksten automatisch gelezen met optische tekenherkenning, en dat gaat nog niet erg goed: de computer leest bijvoorbeeld dexe voor deze of fchapen voor schapen.
 Van der Sijs: “Als je met grote hoeveelheden historische data werkt, moet je daarom voortdurend kritisch naar de resultaten kijken: je moet steeds steekproeven nemen om te zien wat de waarde ervan is, of je de vraag goed hebt gesteld en of de data niet te zeer vervuild zijn. Het heeft pas zin om gevonden resultaten mooi te visualiseren als je er zeker van bent dat ze betrouwbaar zijn. Onderzoekers zouden eigenlijk altijd de ruwe data moeten bewaren, zodat collega-onderzoekers erop kunnen voortbouwen. Voor geesteswetenschappers is dat wel een omslag in de werkwijze.”
Van der Sijs: “Als je met grote hoeveelheden historische data werkt, moet je daarom voortdurend kritisch naar de resultaten kijken: je moet steeds steekproeven nemen om te zien wat de waarde ervan is, of je de vraag goed hebt gesteld en of de data niet te zeer vervuild zijn. Het heeft pas zin om gevonden resultaten mooi te visualiseren als je er zeker van bent dat ze betrouwbaar zijn. Onderzoekers zouden eigenlijk altijd de ruwe data moeten bewaren, zodat collega-onderzoekers erop kunnen voortbouwen. Voor geesteswetenschappers is dat wel een omslag in de werkwijze.”
Historisch taalkundigen zullen bovendien basale kennis moeten krijgen van statistische methodes. Vooral voor jonge taalwetenschappers wordt deze vaardigheid steeds belangrijker, volgens Van der Sijs. “Daarnaast stimuleren de grote hoeveelheden digitale data de samenwerking tussen onderzoekers onderling en tussen onderzoekers en technici. Ik beschouw dat allemaal als pure winst: we kunnen veel van elkaar leren en samen kunnen we grotere en ingewikkeldere problemen aanpakken dan als individuele onderzoeker.”
Oude en nieuwe onderzoeksvragen
Veranderen de onderzoeksvragen eigenlijk door de komst van digitale middelen? Van der Sijs denkt voor haar vakgebied van niet: “Ik geloof dat de fundamentele vragen hetzelfde blijven. Historisch taalkundigen zoeken de wetmatigheden achter taalverandering en taalvariatie. Maar vragen die je vroeger niet kon beantwoorden, probeer je nu wel te beantwoorden. Zoals de vraag of er een relatie is tussen de talige en de niet-talige werkelijkheid. Het is bijvoorbeeld interessant om te zien of er in periodes van onrust, oorlog en verhuizingen meer taalverandering is. Het ligt voor de hand dat het antwoord ‘ja’ is, maar je zou dat willen toetsen. We hebben steeds meer informatie over die verhuizingen. De database met informatie over regionale migratie (de Migmap) kun je op een taalkundige database leggen.”
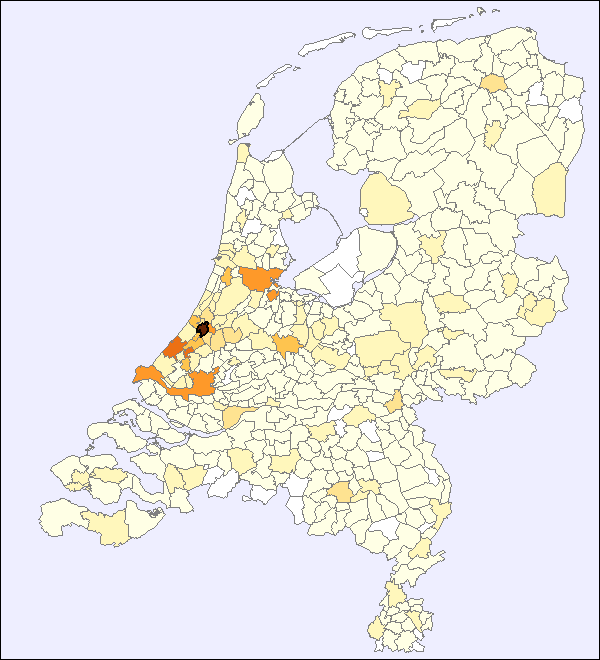 “We weten bijvoorbeeld dat er in de 17e eeuw in Leiden veel Zuid-Nederlanders waren die heel belangrijk waren in de lakenindustrie. Die hebben zeker invloed gehad op dat Leidse dialect. We hebben ook onderzoek gedaan naar Nederlanders die naar Amerika gingen. De veronderstelling was dat die mensen een bepaald dialect hadden meegenomen en dat oorspronkelijke dialect in hun nieuwe woonplaats hadden bewaard. Maar uiteindelijk bleek dat er in Amerika een nieuw Nederlands was ontstaan dat niet geworteld was in één dialect: de dialectsprekers hadden hun taalgebruik aan elkaar aangepast.
“We weten bijvoorbeeld dat er in de 17e eeuw in Leiden veel Zuid-Nederlanders waren die heel belangrijk waren in de lakenindustrie. Die hebben zeker invloed gehad op dat Leidse dialect. We hebben ook onderzoek gedaan naar Nederlanders die naar Amerika gingen. De veronderstelling was dat die mensen een bepaald dialect hadden meegenomen en dat oorspronkelijke dialect in hun nieuwe woonplaats hadden bewaard. Maar uiteindelijk bleek dat er in Amerika een nieuw Nederlands was ontstaan dat niet geworteld was in één dialect: de dialectsprekers hadden hun taalgebruik aan elkaar aangepast.
“Hoe zit het met ander ‘geëxporteerd’ Nederlands, bijvoorbeeld het Nederlands in Zuid-Amerika? Daarheen trokken veel Zeeuwen. Zijn er Zeeuwse sporen te vinden in Suriname en de Nederlandse Antillen? Welke ontwikkeling heeft het Nederlands daar eigenlijk doorgemaakt? Daarover zouden we veel meer willen weten. Met digitale middelen kunnen we voor het eerst antwoorden proberen te vinden op dergelijke vragen. Kortom, de digitale geesteswetenschappen hebben ons een hoop nieuwe mogelijkheden te bieden. En dat is precies de uitdaging van deze nieuwe leerstoel.”
Afbeeldingen: 1. Copyright: Flickr, Archigeek; 2. Nicoline van der Sijs; 3. Voorbeeld van migratiekaart (Meertens Instituut).
Dit artikel is verschenen in de nieuwsbrief (maart 2014) van het Meertens Instituut. Ook interesse in de nieuwsbrief? Klik hier voor meer informatie.