Publicatiedatum: 3 juni 2015
Dialectwoorden in een nieuw digitaal jasje
Op 16 juni lanceert het Meertens Instituut een nieuwe databank: de elektronische Woordenbank van de Nederlandse Dialecten (eWND). Het doel van de eWND is om zoveel mogelijk dialectwoordenboeken digitaal beschikbaar en doorzoekbaar te maken. Zowel taalkundigen als taalliefhebbers kunnen straks alle belangrijke Nederlandse dialectwoordenboeken op één centraal punt raadplegen.
door Mathilde Jansen
 Taalkundige Nicoline van der Sijs werkt al jaren samen met een leger aan vrijwilligers. Op die manier stampt ze in korte tijd grote digitaliseringsprojecten uit de grond. Denk aan de gedigitaliseerde veries van de Statenbijbelvertaling.
Taalkundige Nicoline van der Sijs werkt al jaren samen met een leger aan vrijwilligers. Op die manier stampt ze in korte tijd grote digitaliseringsprojecten uit de grond. Denk aan de gedigitaliseerde veries van de Statenbijbelvertaling.
Maar ook de Etymologiebank, waarin meerdere etymologische publicaties zijn samengebracht. Deze trok sinds de onlinegang in 2010 zoveel bezoekers, dat Van der Sijs bedacht deze formule te herhalen voor dialectwoordenboeken: “Er is blijkbaar een groeiende behoefte om veel gegevens op één plek te kunnen raadplegen.”
Veel handwerk
Eind 2013 kreeg ze voor dit plan geld van het Prins Bernhard Cultuurfonds.Voor de eWND hebben zich de afgelopen anderhalf jaar opnieuw zo’n 75 mensen vrijwillig ingezet. Dankzij hen en een handjevol studenten gaat half juni een voorlopige versie van de eerste databank met Nederlandse dialectwoorden online.
Van der Sijs, die onlangs haar zestigste verjaardag vierde, kan inmiddels niet meer zonder haar vrijwilligers: “Ook dit project bestaat uit heel veel handwerk. Daar verkijk je je altijd weer op. Het is niet enkel woordjes overtikken, maar vooral de data verrijken, zodat de zoekmachine ze ook kan vinden.”
Onverwachtse vondsten
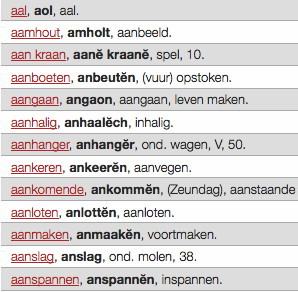 De databank die op 16 juni gelanceerd wordt, bevat zowel oude als jonge dialectwoordenboeken. De oudste bron is een woordenlijst van het Haags uit 1780, vertelt Van der Sijs. De jongste is nu het Thoears Woeardebook (woordenboek van het Limburgse Thorn) uit 2012. Maar wellicht komen daar nog oudere of jongere woordenboeken bij, want de invoer gaat na 16 juni gewoon door. “We zien wel hoe ver we komen”, lacht de hoogleraar.
De databank die op 16 juni gelanceerd wordt, bevat zowel oude als jonge dialectwoordenboeken. De oudste bron is een woordenlijst van het Haags uit 1780, vertelt Van der Sijs. De jongste is nu het Thoears Woeardebook (woordenboek van het Limburgse Thorn) uit 2012. Maar wellicht komen daar nog oudere of jongere woordenboeken bij, want de invoer gaat na 16 juni gewoon door. “We zien wel hoe ver we komen”, lacht de hoogleraar.
Tijdens dit project deed ze ook onverwachtse ontdekkingen. Zo kwam ze laatst allerlei woordenlijstjes tegen in de Driemaandelijkse bladen, over het volksleven in Oost-Nederland, en kreeg ze een klein Zeeuws woordenboekje in handen gedrukt. Ook doken er manuscripten op die nooit eerder gepubliceerd waren, vertelt Van der Sijs:
“Er bestaat een manuscript van de derde druk van het Groningse woordenboek van Molema, met allerlei handgeschreven aantekeningen die nooit zijn gepubliceerd. Die hebben we nu beschikbaar gemaakt. Molema heeft ook een Drents manuscript gemaakt dat nooit eerder gepubliceerd was. Ook stuitten we nog op een typoscript van een Venloos woordenboek.”
Workflow
De selectie van woordenboeken die nu is opgenomen is vrij toevallig, geeft Van der Sijs toe: “Ik heb aan allerlei mensen gevraagd of ze digitale bestanden hadden. Maar de meerderheid waren boeken waarvan ik al een scan had. Soms omdat hier in de bibliotheek dubbele exemplaren waren, of via collega Ewoud Sanders of Google Books. Nieuwe bestanden zijn nog altijd welkom.”
Daarbij hoort wel een waarschuwing, aldus de onderzoeker: als iemand een digitaal bestand kan aanleveren, staat het niet de volgende dag in de databank. Dat blijkt wel als Van der Sijs de workflow beschrijft. Die begint met een scan van het woordenboek. Daarna deelt ze de woordenboeken in in porties van 10 tot 15 bladzijden. Die gaan de vrijwilligers overtikken en aanvullen: ontbrekende woorden, afkortingen, alles moet voluit. Anders herkent de zoekmachine ze niet.
Gepuzzel
Dialectingang, woordsoortinformatie, verkleinvormen, meervoudsvormen en vervoegingen worden allemaal apart vermeld. Vervolgens wordt het geheel nog eens nagekeken door een tweede vrijwilliger. Een derde persoon zet alles over in een tabel. En dan komt misschien wel het moeilijkste deel: er wordt een Nederlands trefwoord toegekend.
 Een speciaal groepje taalkundestudenten buigt zich over de trefwoordtoekenning. Dat is geen sinecure, aldus Van der Sijs: “Soms gaat het om woorden die allang verdwenen zijn in het Standaardnederlands. Om de betekenis daarvan op te sporen maken de studenten veel gebruik van Van Dale, het WNT en het Etymologisch Dialectwoordenboek van Weijnen.”
Een speciaal groepje taalkundestudenten buigt zich over de trefwoordtoekenning. Dat is geen sinecure, aldus Van der Sijs: “Soms gaat het om woorden die allang verdwenen zijn in het Standaardnederlands. Om de betekenis daarvan op te sporen maken de studenten veel gebruik van Van Dale, het WNT en het Etymologisch Dialectwoordenboek van Weijnen.”
Uiteindelijk krijgen alle dialectwoorden een Nederlandse ingang. Op die manier is het makkelijk zoeken in de databank. En kon bij de dialectingang gewoon de originele spelling aangehouden worden: “We zijn niet gaan omspellen, omdat je vaak niet weet waar de spelling voor staat. Vooral bij oudere woordenboeken is dat het geval.”
Nieuwe toepassingen
Na de lancering blijft de databank zich dus uitbreiden. Ook Vlaanderen kent een databank, met een iets andere opzet: http://www.woordenbank.be. Deze bank is door Gentse dialectologen samengesteld, en bevat ook het Woordenboek der Zeeuwse Dialecten. Van der Sijs hoopt ook haar Friese collega’s te enthousiasmeren, zodat straks de hele kaart van Nederland gevuld is. Wellicht kan er op den duur dan ook een kaartapplicatie ontwikkeld worden.
 En zo worden de mogelijkheden voor onderzoek steeds talrijker, besluit Van der Sijs: “Straks kun je oude met jonge woordenboeken vergelijken, of uit één regio. Maar ook kun je kijken naar veranderingen binnen het Nederlandse dialectgebied, zoals de manier waarop sterke werkwoorden zwak worden.”
En zo worden de mogelijkheden voor onderzoek steeds talrijker, besluit Van der Sijs: “Straks kun je oude met jonge woordenboeken vergelijken, of uit één regio. Maar ook kun je kijken naar veranderingen binnen het Nederlandse dialectgebied, zoals de manier waarop sterke werkwoorden zwak worden.”
Semi-automatisch
Haar vrijwilligers zal ze nog hard nodig hebben. Maar Van der Sijs wil ook kijken in hoeverre een deel van de workflow semi-automatisch ondersteund kan worden. Ze ziet mogelijkheden bij het vernederlandsen. “Een woord bestaat uit medeklinkers en klinkers. Vaak zijn de medeklinkers redelijk stabiel en de klinkers niet. De computer kan patronen herkennen en op basis hiervan voorspellingen doen. De computer zou bijvoorbeeld kunnen voorspellen wanneer in een bepaald dialect ie staat voor Standaardnederlands ij, en wanneer voor ie.”
“In het ideale geval suggereert de computer voor de dialectvorm kniepstät de Standaardnederlandse vorm knijpstaart, en voor de dialectvorm niejgien de Standaardnederlandse vorm nieuwtje. Kniepstät is overigens de benaming voor iemand die heel zuinig is. Als de computervoorspellingen redelijk goed zijn, zal dat het toevoegen van de Standaardnederlandse vormen behoorlijk kunnen versnellen.”
De zoekfunctie van de eWND wordt op 16 juni 2015 gelanceerd bij het afscheidssymposium voor Anne Dykstra ‘Wurdboek en Maatskippij’ op de Fryske Akademy; de tekstuitgaven van de verschillende woordenboeken zijn nu al te vinden op http://www.meertens.knaw.nl/dialectwoordenboeken/
Foto's: 1. Nicoline van der Sijs tijdens het symposium dat werd georganiseerd ter gelegenheid van haar zestigste verjaardag eerder dit jaar (foto door Femke Niehof); 2. Fragment uit de Staphorster Woordenlijst (1907); 3. Studenten zoeken Nederlandse trefwoorden bij de dialectwoorden (foto door Femke Niehof); 4. Dialectwoordenboeken (Meertens Instituut)
Dit artikel is verschenen in de nieuwsbrief (juni 2015) van het Meertens Instituut. Ook interesse in de nieuwsbrief? Klik hier voor meer informatie.